



I. Qu'est-ce qu'une API ?▲
Si l'on veut faire une analogie, l'API est au développeur ce que l'UI (User Interface) est à l'utilisateur. C'est donc la partie visible et accessible de notre programme, permettant au monde extérieur de saisir des données et de récupérer le résultat des traitements. Autrement dit, c'est une façade fournissant des fonctionnalités tout en masquant l'implémentation et la mécanique interne. Ce terme est applicable aussi bien à une bibliothèque logicielle qu'à un service web.
API = Application Programming Interface (Interface de Programmation en français)
Les API offrent la possibilité de construire un logiciel par « assemblage » en faisant appel à des solutions tierces externes (cf. la liste des API ci-dessous) permettant de concevoir des architectures orientées services. Cette méthode permet de gagner du temps lors de la phase de développement, car il n'est plus nécessaire d'écrire du code pour faire une tâche s'il existe déjà une API proposant le même service (cf. ci-dessous la liste des API). Outre le gain de temps, cela permet aussi de se concentrer sur la logique propre à son application (la valeur ajoutée).
La majorité des grands noms de l'informatique proposent des API publiques pour interagir avec leurs services :
- Graph API (Facebook) permet d'interagir avec les données de Facebook (publication, importer des photos…) ;
- Google API, Google propose des accès pour l'ensemble de ses services. Si l'on prend Maps par exemple, l'API permet de calculer des trajets, de gérer la conversion de coordonnées GPS/adresses ou encore de connaitre l'altitude liée à une position ;
- Twitter API permet de lire et d'écrire sur un flux Twitter ;
- Pay permet d'intégrer la solution de paiement PayPal dans son application ;
- GitHub API ;
- Flickr API.
Mais aussi de plus en plus d'entreprises qui ne sont pas des « pures players » du web ou de l'informatique, voire des gouvernements et des associations :
- la SNCF (itinéraires, horaires des trains…) ;
- le gouvernement (démarches administratives, données publiques, fiscalité…) ;
- de nombreux autres gouvernements en possèdent aussi.
Et bien sûr de nombreuses API sont apparues pour remplir des services divers et variés :
- WeatherMap pour récupérer les informations météorologiques ;
- Holiday API pour consulter les dates des vacances dans de nombreux pays ;
- fixer.io pour obtenir les taux de change monétaire actuels ;
- LanguageLayer pour détecter la langue d'un texte ;
- MailboxLayer et NumVerify pour vérifier et valider des adresses mail et des numéros de téléphone ;
- OpenAQ pour connaitre la qualité de l'air ;
- des sites d'actualité proposent un accès à leurs données, comme le New York Times ;
- des sites de musique (Spotify, Deezer) ou de vidéo (YouTube, Vimeo, DailyMotion…) proposent des interactions avec leurs services.
Une API est aussi une sorte de contrat entre son auteur et ses utilisateurs. En effet, à tout moment, une API peut changer. Problème, l'API étant utilisée par des personnes externes, il est de la responsabilité du développeur de l'API de lui garantir une certaine stabilité (nom de méthode, paramètres…). Si cette garantie n'est pas tenue, le code des utilisateurs prend le risque d'être « cassé ». Ce contrat (ou plutôt cette promesse ?) est différemment respecté en fonction de l'audience (une grosse API évolue forcément plus doucement qu'une petite), du sens des responsabilités du développeur et de la qualité du code. Il est donc important de faire attention aux choix que l'on fait lors du développement (architecture, nommage…).
En plus de la stabilité, une bonne API est aussi synonyme de performance et d'ergonomie (faciliter l'usage des choses simples et courantes et permettre les actions complexes). Il n'est d'ailleurs pas toujours évident de concilier ces deux aspects.
La principale différence entre une API et une API web est le fait que dans le premier cas, on utilise un langage de programmation pour la manipuler, alors que dans le second cas on utilise un protocole web. Actuellement, la majorité des API web « populaires » utilisent le protocole REST associé au format d'échange JSON.
II. REST▲
REST (Representational State Transfer) est un ensemble de conventions et de bonnes pratiques permettant de construire des services web (!= SOAP qui est un protocole). Elles ont été définies par Roy Fielding dans les années 2000. En voici les grandes lignes.
- L'URI (Uniform Resource Identifier) comme identifiant unique des ressources (système universel d'identification des éléments).
- Les verbes HTTP comme identifiant des opérations : GET (afficher), POST (créer), PUT (mettre à jour), DELETE (supprimer)…
- Les réponses HTTP comme représentation des ressources. Attention, la réponse envoyée n'est pas une ressource, mais la représentation d'une ressource. Il est donc possible pour le client d'obtenir une même ressource sous plusieurs formats : JSON, XML, CSV, HTML…
- Les liens comme relation entre ressources (pour gérer les ressources liées, les pages suivantes/précédentes dans une liste d'éléments…).
- Un paramètre comme jeton d'authentification.
Le style d'architecture REST impose aussi de respecter un certain nombre de contraintes.
- Fonctionnement en mode client/serveur : permet la séparation des responsabilités.
- Sans état : pour le serveur, chaque requête est distincte l'une de l'autre. Celle-ci contient donc l'ensemble des données nécessaires à son traitement par le serveur (pas de mécanisme de session). Cette contrainte permet de conserver une indépendance et évite le maintien d'une connexion entre les deux parties. De plus, cela facilite la répartition des requêtes, l'évolutivité et la tolérance aux pannes, tout en réduisant la consommation mémoire (ce qui permet de traiter une plus grande quantité de requêtes simultanément).
- Cacheable : permet d'améliorer les performances et de réduire les allers-retours réseau, mais implique de gérer la notion de péremption.
Dans un contexte Web, REST est basé sur le protocole HTTP et permet donc de profiter de l'enveloppe (body) et des en-têtes (headers).
II-A. REST vs RESTful▲
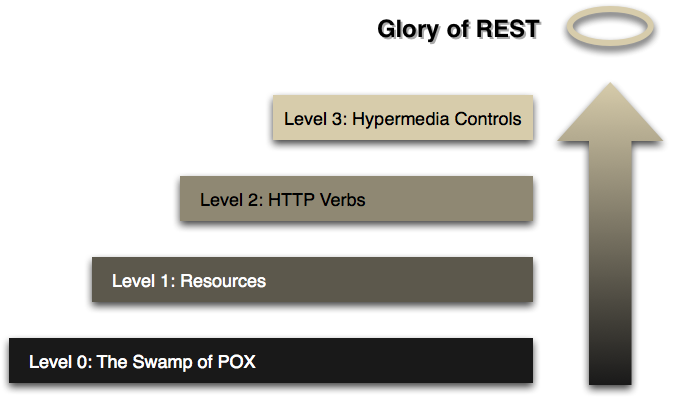
En se basant sur le travail de Roy Fielding, Leonard Richardson a établi un modèle de maturité des services web REST appelé Richardson Maturity Model (RMM). Ce modèle est composé de quatre niveaux permettant d'évaluer une API par rapport aux contraintes REST :
|
|
|
Richardson Maturity Model (https://martinfowler.com/articles/richardsonMaturityModel.html) |
- Niveau 0 : le protocole HTTP est utilisé uniquement à des fins de transport du message (cf. SOAP par exemple). L'ensemble des données transitent par un seul et unique point d'entrée.
- Niveau 1 : introduction de la notion de ressources. Il y a donc désormais plusieurs endpoint (URI) par ressource.
- Niveau 2 : apparition de la notion d'action et d'état, ce qui correspond aux verbes (GET, POST, PUT, DELETE…) et aux codes (200, 404, 500…) en HTTP.
- Niveau 3 : ultime et dernière notion de REST : HATEOAS (Hypertext As The Engine Of Application State). Cela permet de rendre l'API « autodocumentée », c'est-à-dire que l'on peut passer d'une action à une autre via des URL transmises par l'API dans les réponses. Pour illustrer cela, prenons le cas d'un service web de gestion de bibliothèque. Si l'on demande un livre spécifique, l'API va nous retourner un flux JSON avec les données de ce livre ainsi que des liens vers la page de l'auteur, des livres liés (du même genre ou du même auteur par exemple) ou encore un lien permettant d'ajouter le livre à son panier pour l'acheter. Tout cela permet d'enrichir énormément notre API et d'offrir à l'utilisateur des interactions supplémentaires.
Une API est donc RESTful si elle atteint le niveau 3 du modèle RMM. Dans le cas contraire, contentez-vous de parler d'API ou d'API HTTP…
II-A-1. Bonnes pratiques et règles de nommage▲
REST n'est qu'un style d'architecture, il n'y a donc aucune contrainte quant à la façon d'écrire votre code. Malgré tout, l'état de l'art nous apporte un certain nombre de bonnes pratiques pour concevoir une API REST efficace et élégante.
-
URL
-
Privilégier l'utilisation de noms (pour désigner les ressources). Les verbes peuvent tout de même avoir leur utilité lorsque l'on souhaite désigner une action ou une opération :
- /users ;
- /books/5/download.
- Généralement, le standard privilégie l'usage du pluriel (pour intégrer l'ensemble des routes traitant d'un même sujet sous le même préfixe). Le singulier peut malgré tout être utile dans les cas où l'entité est unique et qu'on souhaite l'indiquer de manière claire.
- Pour la casse, le lowercase ou le snake_case est préférable, tout en gardant à l'esprit que le plus important est d'utiliser la même partout !
-
-
Paramètres
-
Path : pour les paramètres obligatoires ou des identifiants de ressources :
- /books/5.
-
Query : pour les paramètres optionnels :
- /books/5?view=compact.
- Body : pour les données à envoyer.
- Header : pour les paramètres globaux à l'ensemble de l'API (token d'authentification, numéro de version…).
-
-
Status HTTP
- 1xx : indique au client qu'il doit attendre quelque chose.
- 2xx : indique au client un succès et lui fournit la réponse attendue.
- 3xx : indique au client un problème d'emplacement (redirection).
-
4xx : indique au client qu'il a fait une erreur :
- 400 (Bad Request) : erreur de syntaxe ;
- 401 (Unauthorized) : il est nécessaire d'être authentifié pour accéder à cette ressource ;
- 403 (Forbidden) : la requête est valide, mais refusée par le serveur ;
- 404 (Not Found) : la ressource n'existe pas ou n'a pas été trouvée ;
- 405 (Not Allowed) : le verbe HTTP demandé n'est pas autorisé pour cette ressource ;
- 422 (Unprocessable Entity) : indique que l'entité fournie en paramètre est incorrecte (très pratique pour gérer les erreurs fonctionnelles) ;
- …
-
5xx : indique au client que le serveur a fait une erreur :
- 500 (Internal Server Error) : erreur interne du serveur ;
- 501 (Not Implemented) : la fonctionnalité demandée n'est pas supportée par le serveur ;
- 503 (Service Unavailable) : service temporairement indisponible ou en maintenance.
- Avec tout ça, il n'est donc plus question de renvoyer un code 2xx avec une entité contenant un bloc d'erreur !
- Gestion des erreurs : les statuts HTTP fournissent une gestion d'erreurs intéressante, mais pouvant manquer de granularité et de précision. Il n'existe malheureusement pas de standard à ce sujet et il est donc nécessaire de définir son propre format d'échange.
-
Filtrage des données
-
Objectifs
- Réduire le volume de données à échanger ou le nombre de requêtes entre client et serveur.
- Cibler des plateformes différentes : standards (sites web, BackOffice…) ou mobiles.
-
Solutions
-
En spécifiant explicitement la liste des champs que l'on souhaite récupérer
- /books?order=up&filter=title,author,year ;
- via un style que l'on aura défini préalablement (minimal, mobile, compact…).
-
-
II-A-2. Versioning▲
Le versioning va principalement intervenir dans le cas où le besoin change et qu'il est nécessaire de faire évoluer la signature du service. Dans ce cas, soit la compatibilité descendante est conservée (c'est-à-dire que les utilisateurs actuels de l'API ne seront pas impactés par les changements), soit elle ne l'est pas. Dans ce dernier cas, il est donc nécessaire de versionner notre API. Il y a plusieurs façons de faire.
-
Via l'URL
- Soit directement dans le path (/api/v1/myEndpoint) ou avec un paramètre (/api/myEndpoint?version=1).
-
(-) Technique simple et pratique à mettre en place, mais qui pose deux soucis :
- on expose un paramètre technique dans l'URI ;
- on rompt avec les principes de REST, et notamment le fait qu'une ressource n'est plus identifiée par une seule et unique URL. De plus, cela peut faire croire à l'utilisateur qu'il existe une ressource différente par version alors que c'est simplement sa représentation (son format) qui change.
- (+) Permet de partager facilement les liens vers l'API (mail, Twitter…).
- Dans la mesure du possible, méthode à éviter, car cela impose de modifier les URL.
-
Via le nom de domaine
- https://v1.myapi.com/myEndpoint/.
-
Via un en-tête HTTP personnalisé
- api-version: 2 ou X-API-VERSION: 2.
- Dans ce cas, L'URL n'est pas modifiée, mais on ajoute un en-tête HTTP personnalisé.
- (+) Simple à mettre en place côté client.
- (-) Redondant par rapport à l'en-tête HTTP standard « Accept ».
-
Via l'en-tête HTTP « Accept »
-
Accept: application/[app].[version]+[format] :
- [app] le nom de l'application ;
- [version] le numéro de version ;
- [format] format de retour désiré (ex. JSON) ;
- ce qui nous donne par exemple : Accept: application/myCustomApi.v2+json ;
- repose sur ce que l'on appelle la « négociation de contenu » (via un type MIME) ;
- (+) méthode élégante et parfaitement conforme à l'esprit REST ;
- (+) il est possible pour le client de demander plusieurs formats, avec un ordre de préférence ;
- (-) complique beaucoup les tests ;
- c'est le client qui décide quelle version du contenu il souhaite et c'est le mieux placé pour savoir quel format et quelle version il est capable de gérer.
-
Il est bien évidemment possible de supporter, côté serveur, plusieurs méthodes de versioning. Libre ensuite au client d'utiliser celle qui lui convient le plus.
Pour compléter ce sujet, cet article de blog détaille comment sont versionnées les principales API du marché. On remarque rapidement que la méthode de l'URI est de loin la plus utilisée, notamment chez les grands acteurs du web (Twitter, Google, Bing Maps, LinkedIn, Tumblr, Yammer…).
Pour compléter ce chapitre sur REST, je souhaite vous partager deux excellents articles en provenance du blog OCTO :
- le premier qui explique comment designer une « bonne » API REST ;
- le second qui aborde l'ensemble des problématiques d'architecture liées à la mise en place d'une API REST.
III. WebAPI▲
À l'origine, ASP.Net WebAPI est apparu avec ASP.Net MVC 4. C'est la solution proposée par Microsoft pour permettre aux développeurs .NET de construire rapidement des services web RESTful pouvant être consommés par une multitude de clients. La principale différence entre WebAPI et MVC est que l'un possède des vues alors que l'autre retourne des données sérialisées (JSON/XML). Avec l'avènement de .NET Core, Microsoft a fusionné les produits ASP.Net MVC et ASP.Net WebAPI (et donc les classes Controller et ApiController) : welcome to ASP.Net Core !
III-A. « Use Case » : construction de notre API▲
Pour mettre en pratique le contenu des articles, notre projet « fil rouge » sera un gestionnaire de bandes dessinées. Nous allons commencer aujourd'hui par la création du modèle via Entity Framework Core ainsi que le développement de nos services web. Ce projet sera enrichi au fur et à mesure des articles (avec un site web de consultation, un site web d'administration et une application mobile).
Voilà la liste des fonctionnalités que je souhaiterais implémenter. Tout ne sera pas forcément intégré dès le début, mais j'enrichirai tout cela au fur et à mesure de l'écriture des articles et du temps que j'ai à ma disposition.
- Afficher de manière simple et sexy la liste de mes BD (compatible avec un affichage smartphone).
- Gérer les fiches d'informations des BD (nom, image de couverture, auteur, collection, éditeur, date de publication, genre…).
- Lier un fichier (PDF/cbz/cbr) à une BD.
- Pouvoir gérer une liste de lectures et un statut lu/non lu.
- Pouvoir afficher des statistiques sur ma bibliothèque (nombre total de BD, nombre total de BD lues, nombre total par genre, par collection…) via des chiffres et des diagrammes.
- Et sûrement plein d'autres choses… !
III-B. Création et initialisation de la solution▲
Pour bien commencer, je vais créer la solution « ComicsManager » qui contiendra trois projets que je vais rapidement détailler.
III-B-1. ComicsManager.API▲
Pour créer ce projet, on va passer par l'assistant de Visual Studio qui nous propose un modèle de projet ASP.Net Core 2.0 pour WebAPI.
|
|
Dans la foulée, j'en ai profité pour cocher la case permettant d'activer le support de Docker (on en reparlera dans un prochain article) et j'ai désactivé l'authentification.
Ce projet va contenir :
- les contrôleurs chargés d'exposer les méthodes au monde extérieur (dans le dossier « Controllers ») ;
- le fichier de configuration « appsettings.json » (contenant notamment la chaine de connexion vers la base de données) ;
- la classe « Program.cs » contenant le point d'entrée de notre application (la fameuse méthode Main !) et l'instanciation du host web ;
- la classe « Startup.cs » contenant les méthodes de configuration (ajout et enregistrement des services principalement).
III-B-2. ComicsManager.Common▲
C'est un projet de type « Class Library » qui contiendra tous les éléments communs aux différents projets (méthodes d'extensions, ViewModels, helpers…). Cela permet de mutualiser du code entre l'ensemble des briques et donc d'éviter la redondance et de faciliter la maintenance. Ce sera très utile dans les prochains articles lorsque l'on développera les briques BackOffice et FrontOffice.
III-B-3. ComicsManager.Model▲
C'est aussi un projet de type « Class Library » qui contiendra les classes de nos objets métier pour la construction de la base de données (Entity Framework en mode Code-First). Nous allons tout de suite aborder plus en détail ce projet dans le chapitre suivant.
III-C. Création du modèle de données▲
Avec Entity Framework Core, nous ne disposons plus du type de fichier EDMX et donc plus de possibilités pour modéliser graphiquement nos entités. De ce fait, le passage par du Code-First est désormais obligatoire. Pour ma part, et même s'il est nécessaire de changer ses habitudes, je trouve que l'on y gagne clairement au change. Le format XML de l'EDMX commençait à dater et la fiabilité n'était pas toujours au rendez-vous (notamment dans le cadre d'une utilisation avec une gestion de code source).
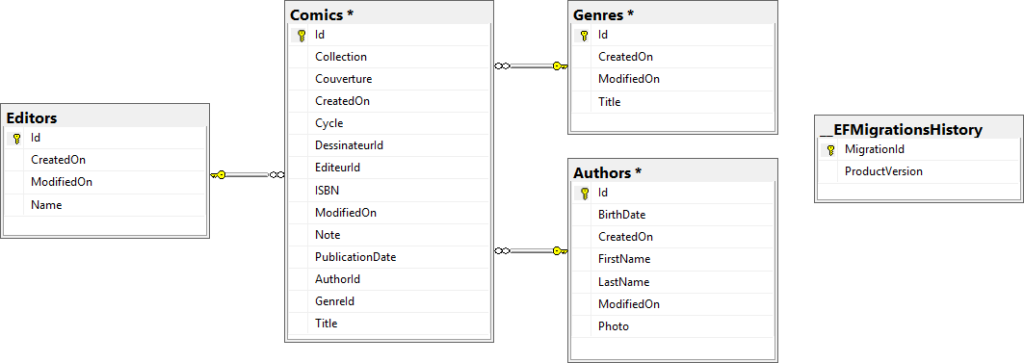
Pour commencer, je vais partir avec quatre entités, que l'on pourra enrichir si nécessaire par la suite en fonction des besoins.
|
|
|
Schéma du modèle de données |
La 1re étape est donc de créer nos classes C# qui représenteront chacune une entité de notre modèle. Je vais prendre un exemple avec la classe Comics :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
public class Comic : BaseEntity
{
[Required]
public string Title { get; set; }
public int Cycle { get; set; }
public string Collection { get; set; }
public int Note { get; set; }
public string ISBN { get; set; }
public DateTime PublicationDate { get; set; }
public string Couverture { get; set; }
public Author Scenariste { get; set; }
public Author Dessinateur { get; set; }
public Editor Editeur { get; set; }
}
L'avantage de ce mode de création est de pouvoir conserver du code C# sur toute la chaine. Il est possible de spécifier des contraintes sur chacune des propriétés, via des attributs. Par exemple, pour la propriété Title, l'attribut [Required] spécifie que la propriété est obligatoire, ce qui se traduit par une colonne Not Null en base de données.
En vrac, je peux citer quelques attributs importants :
- Table : à spécifier sur une classe, permet de dire sur quelle table la classe sera mappée ;
- Column : même chose que pour la table, mais pour une colonne ;
- ForeignKey : permet de spécifier la propriété utilisée comme clé étrangère dans une relation ;
-
DatabaseGenerated : spécifie le type de génération automatique de la valeur
- Computed : génère une nouvelle valeur lors de la création (INSERT) ET de la mise à jour (UPDATE) d'une entité,
- Identity : génère une nouvelle valeur lors de la création de l'entité,
- None : désactive la génération automatique :
- NotMapped : indique que la propriété est exclue du mapping avec la base de données ;
- InverseProperty : permet de définir la propriété « inverse » d'une clé étrangère. Je vais illustrer ça avec un rapide exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
public class Comic
{
public Guid Id { get; set; }
[Required]
public string Title { get; set; }
public Author Scenariste { get; set; }
}
public class Author
{
public Guid Id { get; set; }
public string Name { get; set; }
[InverseProperty("Scenariste")]
public List<Comic> Comics { get; set; }
}
- MaxLength : taille maximale pour un champ de type string ou array ;
- Key : permet de spécifier une ou plusieurs clé(s) primaire(s) ; par défaut, une colonne ayant pour nom « Id » est automatiquement reconnue en tant que clé primaire (ce qui est le cas dans mon exemple).
Chacune de mes entités hérite d'une classe BaseEntity qui contient les propriétés techniques communes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
/// <summary>
/// Propriétés communes à l'ensemble des entités
/// </summary>
public class BaseEntity
{
/// <summary>
/// Identifiant de l'entité
/// </summary>
public Guid Id { get; set; }
/// <summary>
/// Date de création de l'entité (pour le tracking)
/// </summary>
public DateTime CreatedOn { get; set; }
/// <summary>
/// Date de modification de l'entité (pour le tracking)
/// </summary>
public DateTime ModifiedOn { get; set; }
}
Pour gérer la valorisation de ces trois propriétés, j'ai choisi de surcharger les méthodes SaveChanges() et SaveChangesAsync() du DbContext.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
public override int SaveChanges()
{
AddTimestamps();
return base.SaveChanges();
}
public override Task<int> SaveChangesAsync(CancellationToken cancellationToken = default(CancellationToken))
{
AddTimestamps();
return base.SaveChangesAsync(cancellationToken);
}
/// <summary>
/// Gestion du remplissage automatique des colonnes Id/CreatedOn/ModifiedOn
/// </summary>
private void AddTimestamps()
{
var entities = ChangeTracker.Entries().Where(x => x.Entity is BaseEntity && (x.State == EntityState.Added || x.State == EntityState.Modified));
foreach (var entity in entities)
{
var now = DateTime.Now;
if (entity.State == EntityState.Added)
{
((BaseEntity)entity.Entity).Id = Guid.NewGuid();
((BaseEntity)entity.Entity).CreatedOn = now;
}
((BaseEntity)entity.Entity).ModifiedOn = now;
}
}
III-D. Déploiement et migration▲
Dans tout projet, il est rare de conserver le même modèle du début jusqu'à la fin des développements. Il arrive d'avoir oublié des points ou encore de voir évoluer le besoin (suite à une demande du client par exemple). Jusqu'à maintenant, j'utilisais le plus souvent un projet SQL Server Database ( cf. mon article à ce sujet). Avec EF Core, on gagne un nouvel outil pour gérer les évolutions de notre modèle : les migrations.
III-D-1. Créer et supprimer une migration▲
La 1re étape est de créer une migration. Cela s'effectue simplement via la commande : dotnet ef migrations add 'migration_name'. Le framework va comparer l'état actuel du modèle avec la précédente migration (si elle existe) et va générer une classe (héritant de Microsoft.EntityFrameworkCore.Migrations.Migration) contenant deux méthodes : Up et Down. Comme leur nom l'indique, ces deux méthodes contiennent les changements à appliquer pour passer d'une migration à une autre. En même temps, un fichier ModelSnapshot est généré (ou mis à jour s'il existe) et contient l'état courant du modèle. Il est utilisé par .NET Core pour générer les classes de migration.
En cas d'erreur, il est possible de supprimer la dernière migration (suppression du fichier de migration ET annulation de modification du fichier ModelSnapshot) avec la commande dotnet ef migrations remove. Attention, pour être supprimée, la migration ne doit pas avoir été appliquée (cf. ci-dessous). Il est important de passer par cette commande plutôt que de supprimer manuellement le fichier pour éviter d'arriver dans un état incohérent sur le fichier ModelSnapshot (ce qui peut être problématique pour les futures migrations étant donné que l'on se base dessus).
III-D-1-a. Appliquer et annuler une migration▲
Une fois notre migration créée, il est nécessaire de l'appliquer sur notre base de données pour créer effectivement les tables. Cette opération se réalise avec la commande dotnet ef database update. Celle-ci va appeler le code des méthodes Up() de chaque fichier de migration dans l'ordre chronologique. Dans le cas de la 1re migration, une table « __EFMigrationsHistory » va être créée et contiendra chacune des migrations effectuées sur la base.
Pour annuler une migration, il faut passer par la méthode dotnet ef database update 'migration_name_to_cancel'. Dans ce cas, c'est la méthode Down() de la classe qui sera appelée et l'entrée correspondante de la table d'historique sera retirée.
Il est possible de générer un script SQL avec la commande dotnet ef migrations script, en spécifiant éventuellement un scope avec les paramètres « -to » et « -from » . Cela peut être très utile en cas de déploiement sur un nouveau serveur ou lors du déploiement en production par exemple. Dans le même genre, il est bien évidemment possible de modifier les méthodes Up() et Down() des classes de migration pour y intégrer du code personnalisé ( migrationBuilder.Sql("SQL Statement");).
III-D-1-b. Intégration de données▲
Pour terminer sur le sujet des migrations, il peut être nécessaire de devoir créer des données de base (du référentiel) au démarrage de l'application. Pour ce faire, j'ai l'habitude de créer une classe « DataInitializer » , que j'appelle dans la méthode Configure() de ma classe Startup et qui se charge de créer, via du code C#, les données dont j'ai besoin.
III-E. Création des contrôleurs via scaffolding▲
Derrière ce mot barbare, se cache un concept extrêmement pratique permettant de gagner beaucoup de temps lors de la création d'une application. Dans les grandes lignes, Visual Studio va analyser votre modèle de données et va générer les vues (pour notre exemple, nous ne sommes pas concernés par cette partie, notre API ne comporte pas de vues, mais retourne du JSON) et les contrôleurs nécessaires pour réaliser les actions CRUD standards (Create/Read/Update/Delete). Par exemple, pour le cas d'une création, le formulaire avec l'ensemble des champs permettant de créer notre entité sera déjà existant, accompagné des mécanismes de validation et d'insertion en base. Il ne restera plus qu'à apporter les personnalisations nécessaires à notre cas d'utilisation. Cela évite l'écriture de code répétitif !
|
|
Dans le cas d'une WebAPI, le scaffolding fonctionne sur le même principe, mais sans générer de vues HTML. La classe générée va proposer les méthodes suivantes (pour l'entité Editor) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
[Produces("application/json")]
[Route("api/Editors")]
public class EditorsController : BaseController
{
public EditorsController(ComicsManagerContext context)
: base(context)
{ }
// GET: api/Editors
[HttpGet]
public IEnumerable<Editor> GetEditors() ...
// GET: api/Editors/5
[HttpGet("{id}")]
public async Task<IActionResult> GetEditor([FromRoute] Guid id) ...
// PUT: api/Editors/5
[HttpPut("{id}")]
public async Task<IActionResult> PutEditor([FromRoute] Guid id, [FromBody] Editor editor) ...
// POST: api/Editors
[HttpPost]
public async Task<IActionResult> PostEditor([FromBody] Editor editor) ...
// DELETE: api/Editors/5
[HttpDelete("{id}")]
public async Task<IActionResult> DeleteEditor([FromRoute] Guid id) ...
private bool EditorExists(Guid id) ...
}
En quelques clics, tout est donc prêt pour avoir une API fonctionnelle permettant de réaliser les principales opérations de base sur notre entité « Editor » !
Techniquement, le scaffolding repose sur ce que l'on appelle des templates T4. C'est un mécanisme de génération de code propre à Microsoft et qui existe depuis Visual Studio 2005 (il y a quand même quelques ajustements avec l'arrivée de .NET Core) ! On peut trouver les templates de base à cet emplacement : C:\Users{username}.nuget\packages\microsoft.visualstudio.web.codegenerators.mvc\1.0.1\Templates. C'est une très bonne base pour créer ses propres templates. Évidemment, si vous ne souhaitez pas créer les vôtres, des développeurs se sont déjà penchés sur le sujet et il existe plusieurs packages NuGet proposant des templates supplémentaires.
III-F. Anatomie d'un contrôleur WebAPI▲
Les méthodes d'un contrôleur peuvent retourner deux types de résultats.
- Un objet, qui sera donc sérialisé en JSON. Par exemple, pour la méthode
GetEditors(), on retourne un IEnumerable qui sera donc directement sérialisé en JSON dans le corps de la réponse avec un code 200. -
Un IActionResult, plus générique, qui peut représenter pas mal de choses :
-
des erreurs :
- NotFound() qui correspondra à un code 404,
- BadRequest(),
- Forbid() :
-
un succès :
- ObjectResponse(), avec un objet, qui reviendra à retourner directement l'objet avec un code 200,
- File(),
- Redirect() ;
- la classe ControllerBase de Microsoft.AspNetCore.Mvc.Core contient de nombreuses autres méthodes de retour.
-
L'avantage du scaffolding, c'est que les principes de base sont déjà implémentés : vérification de la validité du modèle, conformité des paramètres, vérification de l'existence en base… Il ne reste plus qu'à implémenter les éléments spécifiques aux besoins métier de notre application.
Sur le même principe que ma classe BaseEntity, j'ai tendance à toujours faire hériter mes contrôleurs d'une classe BaseController. Cela me permet de centraliser les éléments communs, comme le DbContext, la configuration, le logger… Les services sont injectés dans le constructeur du contrôleur et sont directement passés au constructeur de la classe parente (nous verrons cela plus en détail dans le chapitre dédié à l'injection de dépendances). Cette classe permet aussi de mettre des méthodes communes à disposition de l'ensemble des contrôleurs.
III-G. IoC et Injection de dépendances▲
L'inversion de contrôle est un concept architectural permettant, notamment, de remplacer et de surcharger les comportements natifs du framework .NET. C'est aussi un formidable moyen architectural pour rendre une application robuste et pour faciliter le découpage des responsabilités en modules. Son implémentation la plus connue est l'injection de dépendances et, dans .NET Core, ce mécanisme est désormais intégré de manière native. Le framework s'appuie d'ailleurs énormément dessus pour faciliter sa modularité et sa flexibilité. Il existe aussi des conteneurs IoC tiers, comme Unity, Ninject ou StructureMap. Dans la plupart des cas, celui de Microsoft va suffire, mais dans le cas où vous avez besoin de fonctionnalités avancées ou que vous êtes encore en .NET classique, cela peut être utile.
Un conteneur IoC joue essentiellement deux rôles:
- un rôle de catalogue, contenant l'ensemble des types abstraits (interfaces) et leur implémentation (un dictionnaire ). Grâce à cela, le conteneur est capable de savoir, pour chaque type abstrait, l'implémentation correspondante. Le remplissage de ce catalogue est à la charge du développeur, et dans le cas de .NET Core, il se réalise dans la méthode ConfigureServices() de la classe Startup. Le conteneur s'appelle IServiceProvider ;
- un rôle de chef d'orchestre, pour instancier automatiquement les dépendances demandées par chaque classe avec le bon scope (il en existe quatre, dont j'ai déjà parlé dans mon article précédent : Instance, Transient, Singleton et Scoped). Pour demander une dépendance, il suffit de l'ajouter dans le constructeur de sa classe. Il suffira ensuite de l'enregistrer pour qu'elle soit disponible.
En .NET Core, l'injection de dépendances est beaucoup utilisée pour ajouter des nouvelles fonctionnalités à la plateforme (AddMVC(), AddIdentity(), AddDbContext()…). En coulisse, ces méthodes sont simplement des raccourcis pour enregistrer les différents composants nécessaires. Décompilons par exemple la DLL Microsoft.AspNetCore.Mvc.dll et regardons le code de la méthode AddMvc :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
/// <summary>
/// Adds MVC services to the specified <see cref="T:Microsoft.Extensions.DependencyInjection.IServiceCollection" />.
/// </summary>
/// <param name="services">The <see cref="T:Microsoft.Extensions.DependencyInjection.IServiceCollection" /> to add services to.</param>
/// <returns>An <see cref="T:Microsoft.Extensions.DependencyInjection.IMvcBuilder" /> that can be used to further configure the MVC services.</returns>
public static IMvcBuilder AddMvc(this IServiceCollection services)
{
if (services == null)
{
throw new ArgumentNullException("services");
}
IMvcCoreBuilder mvcCoreBuilder = MvcCoreServiceCollectionExtensions.AddMvcCore(services);
MvcApiExplorerMvcCoreBuilderExtensions.AddApiExplorer(mvcCoreBuilder);
MvcCoreMvcCoreBuilderExtensions.AddAuthorization(mvcCoreBuilder);
MvcServiceCollectionExtensions.AddDefaultFrameworkParts(mvcCoreBuilder.get_PartManager());
MvcCoreMvcCoreBuilderExtensions.AddFormatterMappings(mvcCoreBuilder);
MvcViewFeaturesMvcCoreBuilderExtensions.AddViews(mvcCoreBuilder);
MvcRazorMvcCoreBuilderExtensions.AddRazorViewEngine(mvcCoreBuilder);
MvcRazorPagesMvcCoreBuilderExtensions.AddRazorPages(mvcCoreBuilder);
TagHelperServicesExtensions.AddCacheTagHelper(mvcCoreBuilder);
MvcDataAnnotationsMvcCoreBuilderExtensions.AddDataAnnotations(mvcCoreBuilder);
MvcJsonMvcCoreBuilderExtensions.AddJsonFormatters(mvcCoreBuilder);
MvcCorsMvcCoreBuilderExtensions.AddCors(mvcCoreBuilder);
return new MvcBuilder(mvcCoreBuilder.get_Services(), mvcCoreBuilder.get_PartManager());
}
On note que le fonctionnement est identique à ce que nous faisons dans la méthode Startup : les différents services et composants nécessaires au bon fonctionnement de MVC sont ajoutés les uns après les autres via des méthodes Addxxx(…).
Il est aussi possible d'injecter une dépendance uniquement sur une action (via [FromServices] devant le paramètre) ou même dans une vue (via @inject).
L'un des gros avantages de l'injection de dépendances est de faciliter la mise en place des tests unitaires. En effet, passer par des interfaces implique que le consommateur de cette dernière n'a plus à se préoccuper du fonctionnement de l'interface, mais uniquement de sa signature. Il est donc très simple d'utiliser plusieurs implémentations différentes à partir du moment ou elles respectent la même interface. Par exemple, en production notre service d'accès aux données va utiliser une implémentation vers SQL Server. Dans le cadre de nos tests, on peut avoir envie de lui fournir une implémentation qui simule l'accès aux données à partir de « fausses données ». De même, si un jour on souhaite changer de fournisseur de données (passage à SQLite), il suffira de changer l'implémentation (ce n'est pas toujours aussi simple malheureusement !).
Pour terminer sur cette partie, voilà le contenu de la méthode ConfigureServices() de ma classe Startup :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
services.AddLogging();
services.AddMemoryCache();
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
// Authentication
services.AddIdentity<ApplicationUser, IdentityRole>()
.AddEntityFrameworkStores<ApplicationDbContext>()
.AddDefaultTokenProviders()
.AddPasswordValidator<UsernameAsPasswordValidator>();
// Add email service
services.AddTransient<IEmailSender, EmailSender>();
// Service de messages
services.AddTransient<IMessageManager, MessageManager>();
// Localization
services.AddLocalization(options => options.ResourcesPath = "Resources");
services.AddMvc(config =>
{
// Global exceptions handler
config.Filters.Add(typeof(GlobalExceptionsFilter));
});
// Paging
services.AddPaging();
III-H. Fichier de configuration▲
Dans une application .NET Core, la gestion de la configuration est un peu différente de ce à quoi on avait l'habitude jusqu'à maintenant. Désormais, tout passe par un fichier appsettings.json (c'est le nommage standard, il est évidemment possible de mettre ce que l'on veut) contenant l'ensemble des clés de configuration :
2.
3.
4.
5.
6.
7.
8.
9.
{
"ConnectionStrings": {
"DefaultConnection": "Server=localhost;Database=MyDatabase;Trusted_Connection=True;MultipleActiveResultSets=true"
},
"AppSettings": {
"DocumentsDirectory": "C:\\Temp\Documents",
"CacheDurationInHours": 24
}
}
Pour charger la configuration, il suffit d'utiliser le code suivant dans le constructeur de notre classe Startup. C'est à ce moment que l'on peut personnaliser le fichier de configuration en fonction du nom de la machine ou du type d'environnement (développement, préprod, prod…). C'est très pratique lors de la phase de développement pour permettre à chaque développeur d'avoir sa propre configuration.
2.
3.
4.
5.
6.
7.
8.
9.
public Startup(IHostingEnvironment environment)
{
Configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile($"appsettings.{Environment.MachineName}.json", optional: true)
.AddJsonFile($"appsettings.{environment.EnvironmentName}.json", optional: true)
.AddEnvironmentVariables()
.Build();
}
En termes d'utilisation, il est très simple de mapper notre configuration sur une classe C# (qui contiendra l'ensemble des paramètres spécifiés dans le fichier json), qui s'utilisera ensuite comme un service à injecter dans nos constructeurs :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
// Mapping de la configuration
services.AddOptions();
services.Configure<AppSettings>(Configuration.GetSection("AppSettings"));
...
// Utilisation
public MyConstructor(IOptions<AppSettings> config)
{
var cacheDuration = config.Value.CacheDurationInHours;
}
III-I. Les logs▲
Par défaut, .NET Core fournit un service de log.
Pour l'activer, il suffit d'appeler services.AddLogging() dans la méthode ConfigureServices() de notre classe Startup puis de le configurer dans la méthode Configure(). Cela passe par l'interface ILoggerFactory qui propose plusieurs possibilités :
- AddConsole() : à utiliser en développement uniquement, peut causer des problèmes de performances ;
- AddDebug() : va permettre la mise en place de l'affichage des logs dans la console de développement de Visual Studio (le minimum dans une phase de développement). Il est évidemment possible de filtrer le niveau de log minimal requis (via LogLevel.Error par exemple en paramètre ou encore via une expression lambda qui proposera plus de souplesse) ;
- AddEventLog() : écrit dans l'EventViewer Windows (uniquement valable sous Windows du coup) ;
- AddAzureWebAppDiagnostic() : si vous êtes sous Azure, va écrire les logs dans un fichier texte hébergé dans le système de fichiers d'Azure.
Il est bien évidemment possible d'utiliser des packages tiers, comme Log4Net, NLog ou encore Serilog. Les trois s'installent sous la forme de packages NuGet. Ils permettent plus de souplesse dans la configuration et ouvrent la possibilité à des scénarios plus avancés. Je pense en particulier aux logs fichier ou aux logs en base de données, à la purge automatique, à la mise en place d'un format particulier pour les messages de log… Avec NLog par exemple, il est possible de configurer plusieurs cibles, avec pour chacune un filtrage sur la criticité du log. Par exemple, je souhaite tout logger en base de données, mais uniquement dans un fichier texte les logs de niveau erreur et critique. De plus, je voudrais envoyer un mail à une liste de diffusion en cas de log critique. Avec NLog, ce scénario est parfaitement possible.
III-J. Gestion des erreurs▲
Toute bonne application doit être équipée d'un bon système de gestion des erreurs. En plus de try/catcher les blocs sensibles de mes applications, une bonne habitude que j'ai prise est de créer un handler global d'exception pour centraliser la gestion des erreurs (et surtout de capter les erreurs oubliées :)) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
public class GlobalExceptionsFilter : IExceptionFilter
{
private readonly ILogger _logger;
public GlobalExceptionsFilter(
ILoggerFactory logger)
{
if (logger == null)
{
throw new ArgumentNullException(nameof(logger));
}
_logger = logger.CreateLogger<GlobalExceptionsFilter>();
}
public void OnException(ExceptionContext context)
{
_logger.LogError(context.Exception, "");
}
}
Il suffit ensuite d'ajouter notre filtre à la configuration du service MVC et le tour est joué :
2.
3.
4.
services.AddMvc(config =>
{
config.Filters.Add(typeof(GlobalExceptionsFilter));
});
IV. Tests▲
Au cours des développements, il est indispensable de pouvoir facilement tester notre API. Pour les méthodes GET, on peut simplement se servir d'un navigateur web et exécuter une requête. Par contre, pour les autres types de requêtes c'est plus compliqué (POST/PUT par exemple). Dans ce cas, il existe des outils pour nous faciliter la vie, et en particulier PostMan que j'utilise régulièrement (https://www.getpostman.com/). Le gros avantage de cet outil est de conserver un historique des exécutions et de pouvoir créer et gérer des collections de requêtes. C'est extrêmement pratique pour pouvoir rejouer rapidement et facilement un ensemble de requêtes (pour réaliser des tests en masse).
|
|
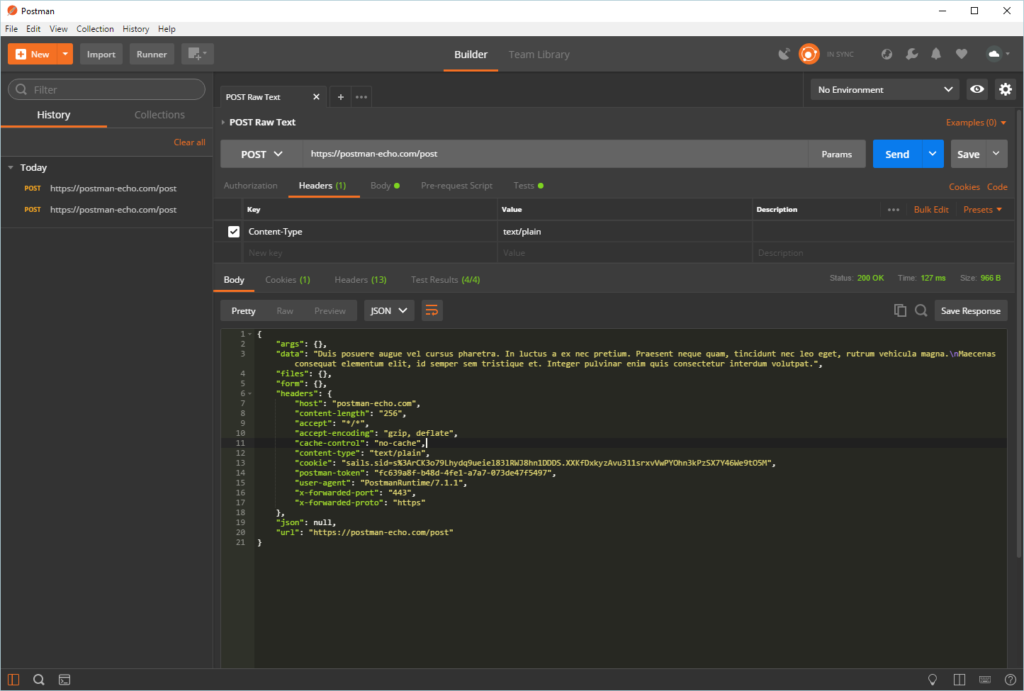
Côté test unitaire, c'est un gros morceau, et j'en parlerai dans un autre article, car c'est important
V. Documentations▲
Pour que notre API soit pratique et agréable à utiliser, et en particulier dans le cas d'une API publique, il est indispensable de mettre à disposition une documentation complète. Pour cela, j'utilise un outil très pratique : Swagger !
Swagger se met en place en quelques minutes sur un projet Web API Core en trois étapes :
- ajout du package NuGet Swashbuckle.AspNetCore ;
- ajout du service :
services.AddSwaggerGen(config => { config.SwaggerDoc("v1", new Info { Title = "ComicsManager API Documentation", Version = "v1" }); });- configuration du service :
2.
3.
4.
5.
app.UseSwagger();
app.UseSwaggerUI(options =>
{
options.SwaggerEndpoint("/swagger/v1/swagger.json", "ComicsManager API Documentation");
});
Il suffit ensuite de démarrer notre projet pour générer notre documentation et l'afficher via http://mon_url/swagger :
|
|
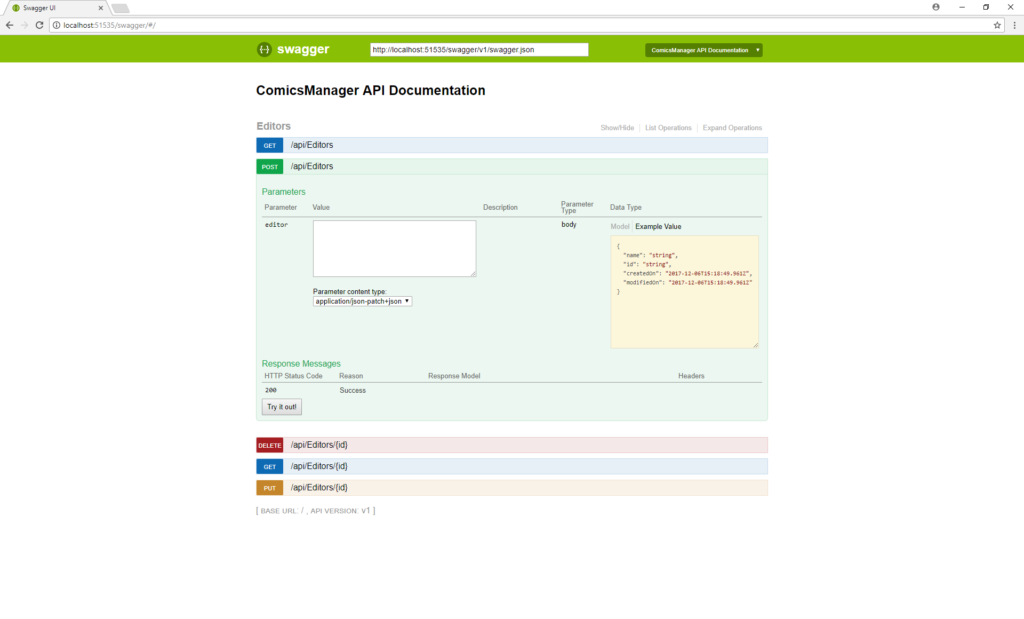
On se retrouve devant une interface moderne affichant l'ensemble des endpoints de nos contrôleurs. Pour chacun, il est possible de consulter la documentation, un exemple du format de retour et la possibilité de tester l'API (on peut presque se passer de PostMan ;)).
VI. Conclusion▲
Pour conclure, vous aurez remarqué qu'il est désormais très facile et très rapide de concevoir une API web pour ses projets. En quelques minutes, EF Core permet de construire notre base de données et le scaffolding de Visual Studio de générer nos squelettes de contrôleurs API. La difficulté se trouve donc dans la « bonne » conception de notre modèle (mais ce n'est pas le sujet de cet article) et surtout de notre API. Et c'est sur ce point que l'expérience et le savoir-faire du développeur vont faire la différence entre une API et une excellente API. Et cela sera d'autant plus important si votre API a pour vocation d'être publique et utilisée par tout un chacun. Dans ce cas, les problématiques de performances deviendront critiques et l'ergonomie sera essentielle à la réussite et à l'adoption de votre service !
Le prochain article abordera la consommation de notre API par des clients, en commençant avec les technologies ASP.Net MVC (pour créer un BackOffice) et AngularJS (pour réaliser un client permettant de visualiser nos bandes dessinées).
Pour finir, j'ai hébergé le code de l'application sur GitHub : https://github.com/AnceretMatthieu/ComicsManager (et ici). Je vous invite à aller y faire un tour pour creuser le sujet et éclaircir certains blocs de code que je n'aurais pas détaillés ici.
VII. Remerciements▲
Nous tenons à remercier Matthieu Anceret qui nous a aimablement autorisés à publier son tutoriel :WebAPI et ses utilisations (2) - Construction de notre API. Nos remerciements également à Claude Leloup pour la relecture orthographique.