




I. Introduction▲
Depuis quelques années, les ORM (Object-Relational Mapping) ont permis aux développeurs « d'oublier », ou plutôt de masquer, la tâche d'écriture et de gestion du code SQL. Pour nous autres, développeurs .NET, je peux citer Entity Framework et Code Fluent. Ces outils permettent de gagner du temps (génération de codes automatiques par exemple) et offrent la possibilité de travailler avec des objets (contrairement à une base SQL qui est relationnelle).
Tout ceci est extrêmement pratique, mais cela ne représente qu'une infime partie de ce qu'est une base de données dans un projet informatique. Le modèle est une chose, mais il ne faut pas oublier les procédures stockées, les fonctions, les services brokers, la configuration… Tous ces éléments représentent notre référentiel. Il faut bien garder à l'esprit que ce référentiel va évoluer au fur et à mesure de l'avancement du développement du projet. Tout comme le code applicatif, il est donc très important, voire essentiel, d'avoir à disposition une « image » à jour de notre référentiel ainsi qu'un historique des modifications qu'on lui a fait subir. De plus, la possibilité de manipuler et utiliser ce référentiel pour pouvoir le déployer facilement et rapidement vers un environnement est un atout indéniable.
Enfin, un projet de développement informatique se faisant rarement seul, il est nécessaire de pouvoir partager et synchroniser ce référentiel avec l'ensemble de l'équipe.
Pour cela, il existe bien sûr une solution et c'est l'objet de cet article : les projets SQL Server Database.
II. Qu'est-ce que c'est ?▲
SQL Server Database est un type de projet Visual Studio, disponible à partir de la version 2010 de l'IDE (mais largement amélioré à partir de la version 2013), malheureusement méconnu et peu (ou mal !) utilisé. Il repose sur l'outillage SQL Server Data Tools (fourni par défaut à partir de Visual Studio 2013).
Dans les grandes lignes, ce type de projet va permettre de transformer votre base de données en une série de fichiers textes (.sql) la décrivant. Les intérêts de cette solution sont multiples :
- modification aisée (via des designers pour certains types de fichiers) directement dans Visual Studio Intégration à Visual Studio et donc…
- … archivage simplifié ainsi que gestion de l'historique ;
- projet compilé et donc détection des erreurs au plus tôt (attention tout de même, ce mécanisme ne couvre pas tous les types d'erreurs) ;
- compatibilité avec la fonctionnalité « Code Analysis » de Visual Studio ;
- recherche !
- support de l'IntelliSense et la coloration syntaxique.
Je souhaite particulièrement insister sur l'aspect archivage avec un gestionnaire de code source. Cette fonctionnalité est particulièrement importante, et ce pour plusieurs raisons :
- gestion simple de l'évolution du schéma de la base de données (de la même façon que pour le code source) ;
- maintien de la cohérence entre la BDD sur le serveur SQL et le projet Visual Studio ;
- maintien d'un historique des modifications et mise à disposition d'outils de comparaison et de rollback ;
- intégration de la documentation directement dans le code SQL ;
- dans le cas de TFS, liaison avec les WorkItems/Bug, ce qui permet de grouper un ensemble de modifications (par fonctionnalité par exemple).
III. Un projet SQL Server Database en détail▲
Je vais désormais essayer d'illustrer les différentes possibilités d'un projet SQL Server Database avec quelques exemples. Premièrement, la création du projet. Le template se trouve dans la rubrique « Other Languages » -> « SQL Server ».
|
|
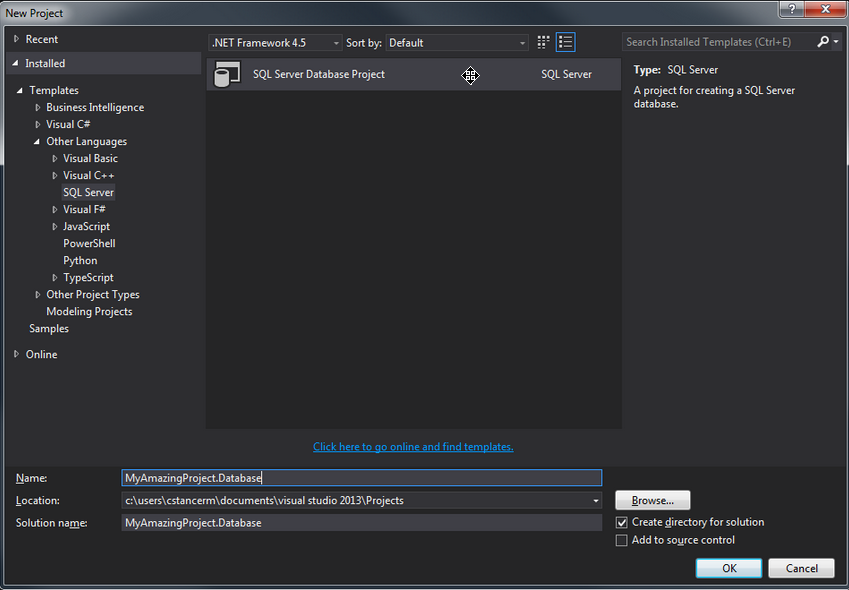
De base, le projet ne contient aucun élément. Je vous conseille d'ores et déjà de créer des dossiers pour mieux organiser votre futur référentiel de base de données. J'ai pour habitude de créer les dossiers suivants :
- Comparisons ;
- Functions ;
- Migrations : j'y stocke les scripts SQL me permettant de passer ma base d'une VX vers une VX+1, et ce pour chaque nouvelle version ;
- Security : contient les scripts liés à la gestion des droits ;
- Snapshots ;
- Stored Procedures ;
- Tables ;
- Views.
Bien évidemment, libre à vous d'organiser comme bon vous semble votre projet.
Une fois le projet créé, nous pouvons passer à sa configuration. Un projet SQL Server Database permet de paramétrer très finement de nombreux réglages. Ces réglages sont accessibles à partir des propriétés du projet.
|
|
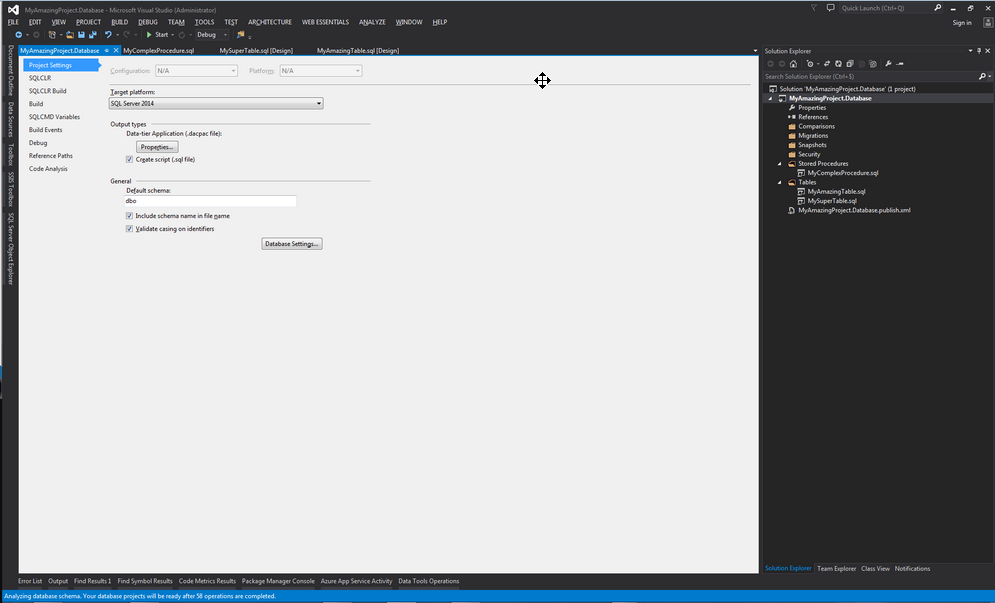
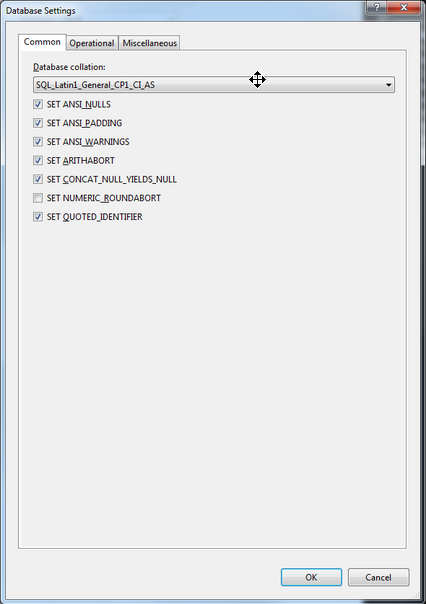
À ce niveau, les réglages essentiels touchent à la version SQL cible et au schéma par défaut. Mais en cliquant sur le bouton « Database Settings », une fenêtre bien plus complète (et complexe !) s'affiche.
Les trois onglets concernent des réglages assez avancés à propos de la base de données :
|
|
|
|

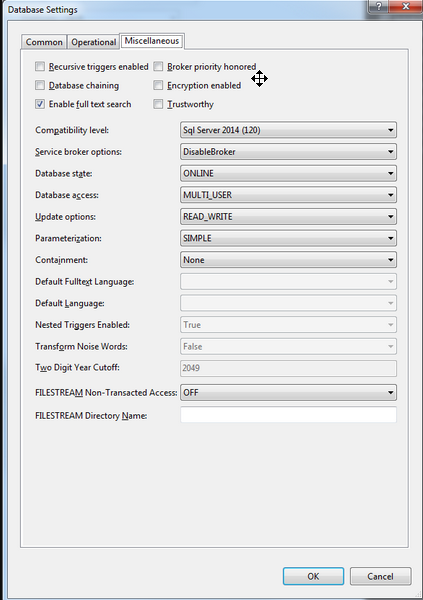
Une fois notre projet configuré, il est désormais temps de créer notre première table. Pour ce faire, Visual Studio met à notre disposition un éditeur graphique. Celui-ci est extrêmement pratique, car il permet de visualiser rapidement l'ensemble des colonnes dans l'encart en haut à gauche et les éléments spécifiques (clés primaires/étrangères, index) en haut à droite tout en ayant un visuel sur le code SQL généré en bas de l'écran.
|
|
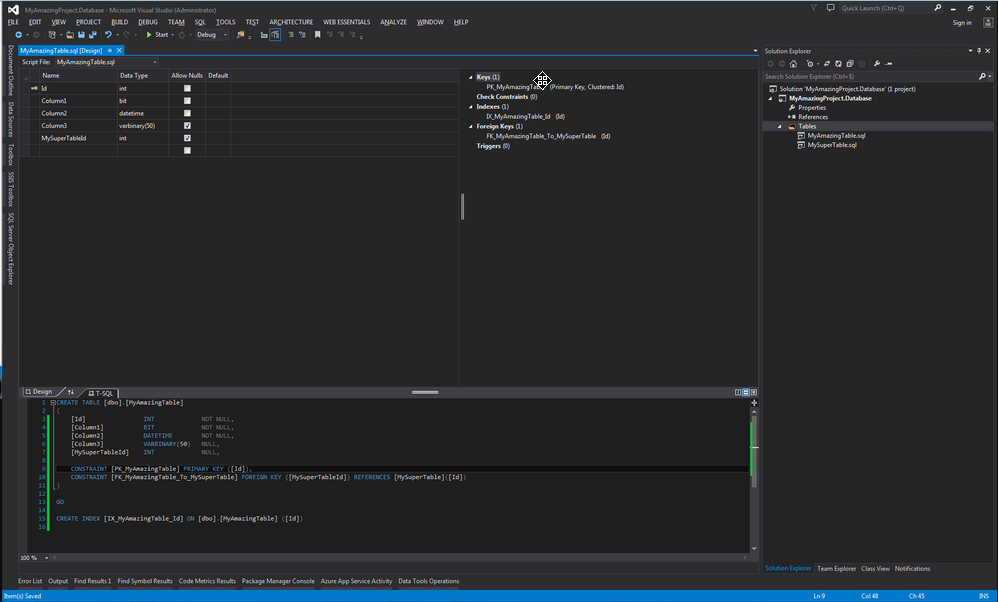
Pour cet exemple, j'ai choisi de créer une table simple avec cinq colonnes, une clé primaire indexée et une clé étrangère.
Il est très important de noter que les projets SQL Server Database fonctionnent sur le modèle déclaratif, c'est-à-dire que l'on va écrire des scripts permettant de dire comment la base doit être et non pas comment y arriver. Autrement dit, on va écrire uniquement du code SQL de type CREATE et pas de DROP ou d'ALTER. C'est le moteur de Visual Studio (via le processus de déploiement) qui va se charger de faire le travail de comparaison pour obtenir l'état voulu.
À noter qu'il est possible de réaliser des requêtes entre plusieurs bases de données. Pour cela, comme pour un projet C#, il faut référencer la base dans le projet (References -> Clic droit -> Database Reference). On peut faire référence à une autre base SQL, à un autre projet SQL Server Database ou encore à un .dacpac. Cette manipulation va créer une variable qui pourra être utilisée dans les scripts pour cibler cette autre base de données.
IV. L'outil « Schema Compare »▲
L'une des fonctionnalités phares d'un projet SQL Server Database est la comparaison de schémas. Cet outil permet de comparer le contenu du projet avec une base de données, un fichier .dacpac, un autre projet SQL ou encore un fichier EDMX (Entity Framework).
Il affiche un résumé des différences (ajouts, modifications et suppressions) et propose de mettre à jour la cible à partir de la source. On peut donc, en fonction des cas, mettre à jour notre projet à partir d'une base de données existante ou inversement mettre à jour une base de données après avoir effectué des modifications sur notre projet.
|
|
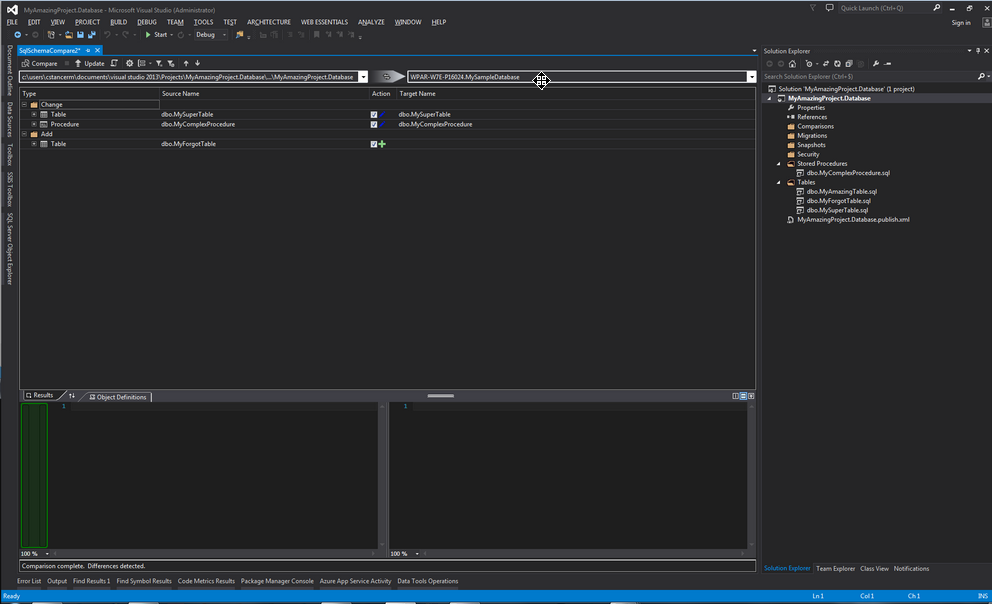
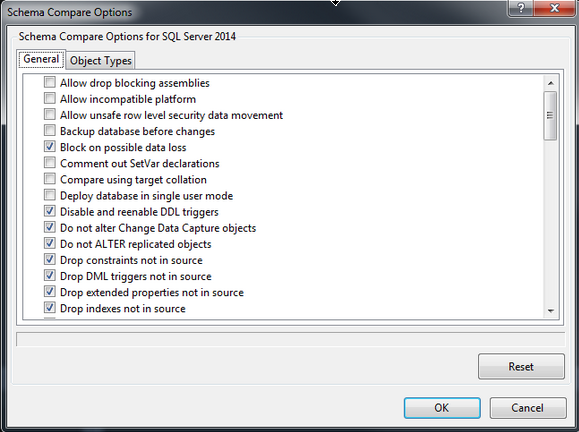
L'outil de comparaison possède lui aussi de nombreuses options (qu'il est possible d'atteindre via le bouton en forme de roue crantée à côté des boutons de comparaison et de mise à jour). L'une des plus utilisées est sans doute « Block on possible data loss », qui permet de stopper la procédure de mise à jour en cas d'éventuelle perte de données (par exemple, si j'ajoute une colonne non nulle à une table possédant déjà des données, si cette case est cochée, le processus de mise à jour sera bloqué).
Il en existe beaucoup d'autres, par exemple pour ignorer des choses ou pour supprimer des éléments uniquement dans la cible et non dans la source.
|
|
Enfin, il est possible de sauvegarder un modèle de comparaison (cible, source et paramétrage) dans le projet pour pouvoir le rejouer facilement. J'ai pris l'habitude d'avoir un fichier de comparaison par environnement (développement, préprod, prod), un local et un avec l'EDMX de la solution (je travaille souvent avec Entity Framework).
V. L'outil « Data Comparison »▲
Sur le même principe que l'outil de comparaison de schéma, il est possible de réaliser des comparaisons de données. Pour cela, il faut se rendre dans le menu « Tools » de Visual Studio -> « SQL Server » puis « New Data Comparison ».
|
|
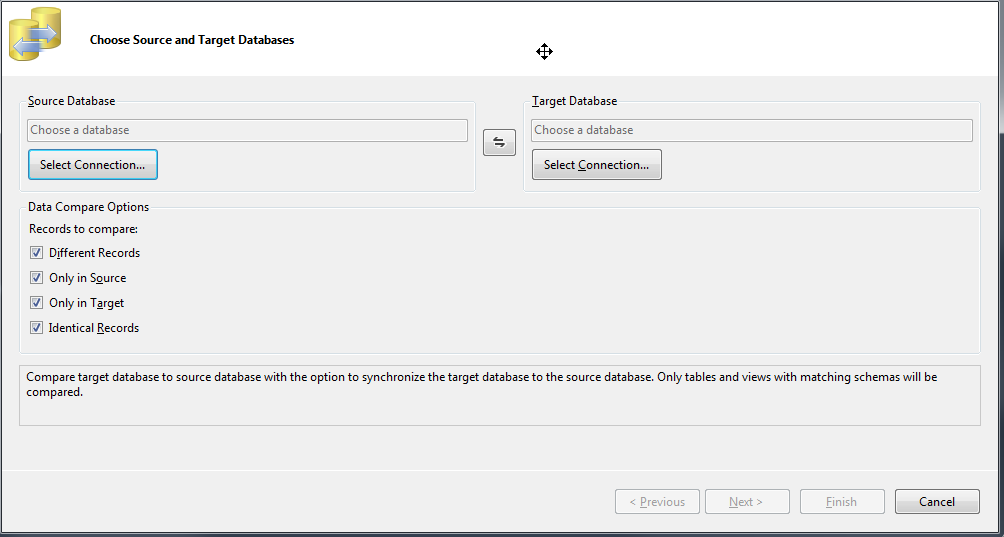
Il suffit de choisir les bases de données source et cible, de configurer les quelques options de comparaison et éventuellement de choisir un sous-ensemble de tables et/ou de vues sur lesquelles effectuer la comparaison (sinon, elle est effectuée sur la totalité des tables et des vues).
Une fois la comparaison effectuée, un bilan s'affiche. Dans la partie haute, pour chaque table/vue, est indiqué le nombre de lignes différentes et identiques ainsi que le nombre d'éléments présents uniquement dans la source ou uniquement dans la cible. En cliquant sur l'une de ces lignes, on peut accéder aux détails (qui vont s'afficher dans la partie basse, avec un onglet par type). Dans le cas de la capture ci-dessous, l'onglet mis en avant est celui des lignes différentes. Les valeurs différentes sont indiquées en gras.
|
|
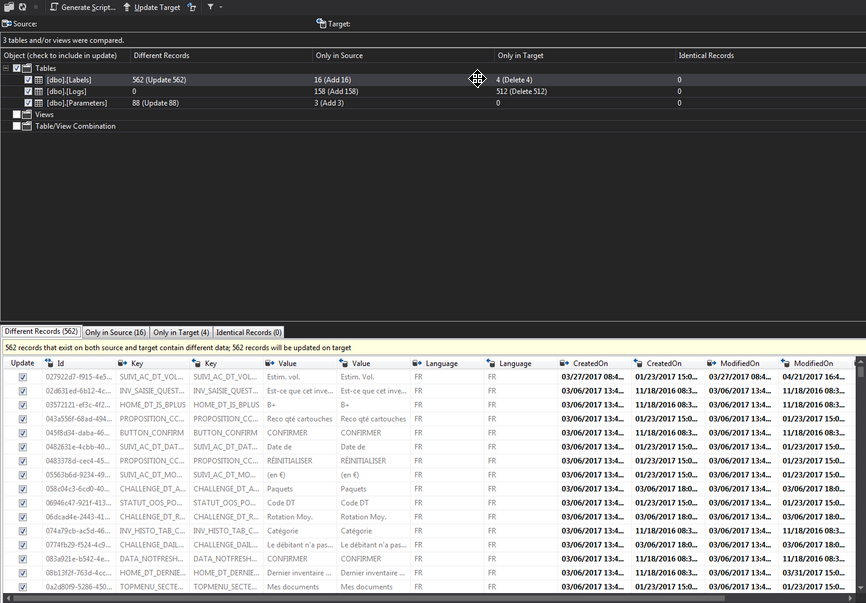
À partir de là, il est possible de générer un script SQL de mise à niveau ou encore de réaliser directement la mise à niveau via l'éditeur de Visual Studio. De la même façon que pour les comparaisons de schémas, il est possible de sauvegarder une comparaison de données.
VI. Les « Snapshots »▲
Les « Snapshots », ou fichiers .dacpac (Data-Tier Application), sont des archives zip représentant notre base de données à un instant T. C'est en quelque sorte l'équivalent de notre projet SQL Server Database. Si l'on s'amuse à extraire le contenu d'un fichier .dacpac, on se retrouve avec plusieurs éléments :
- DacMetadata.xml/DacOrigin.xml : contient des métadonnées ;
- Model.xml : contient la description complète du schéma de la base + la configuration ;
- Model.sql : équivalent simplifié du fichier ci-dessus, mais au format SQL ;
- Pre/PostDeploy.sql : les opérations de pré/post déploiement Refactor.xml : les opérations de refactoring.
L'un des intérêts de ce type de fichier est de pouvoir partager facilement une « image » d'une base de données (sans les données) avec des tiers. Personnellement, je m'en sers très souvent pour conserver une « image » de la base de données à chaque nouvelle version (livraison) de mon projet. Il suffit ensuite de les déposer dans un dossier « Snapshots » de notre projet sur TFS. Cela permet de générer très facilement des scripts de migration/mise à niveau ainsi que de revenir à une version antérieure du schéma (pour corriger des bogues sur une précédente version par exemple).
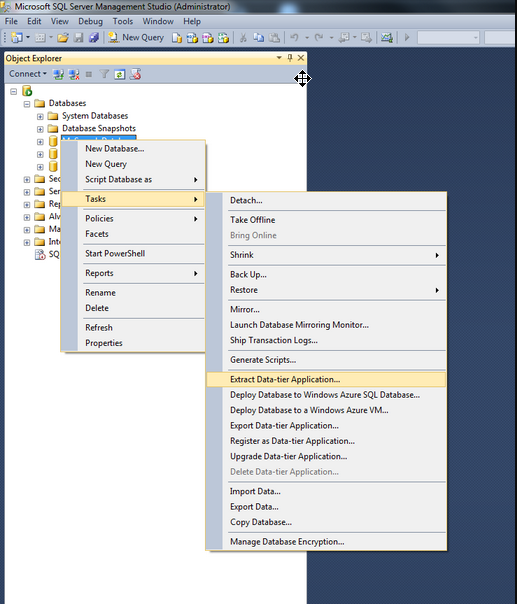
Pour créer un fichier .dacpac, il y a plusieurs méthodes :
-
via SQL Server Management Studio :
-
via l'utilitaire « SqlPackage.exe » ;
- via Visual Studio : la compilation d'un projet SQL Server Database génère un fichier .dacpac.
Pour déployer un fichier .dacpac, on peut utiliser les mêmes outils que pour le créer.
Le projet SQL Server Database propose lui aussi un outil de déploiement (disponible en faisant clic droit sur le projet -> Publish…). Comme avec la majorité des outils, il est possible de configurer « aux petits oignons » notre processus de déploiement et, bien évidemment, de sauvegarder notre paramétrage dans un fichier XML (que l'on peut ajouter à notre projet pour pouvoir le rejouer ensuite à loisir).
Toujours à propos du déploiement, il est possible de créer des scripts de pré/post déploiement (configurables via la propriété « BuildAction » du fichier) qui seront exécutés lors du processus de déploiement. Cela permet de personnaliser un peu ce processus qui est entièrement géré par le système (par exemple, pour insérer des données par défaut).
VII. Le « Refactoring intelligent »▲
Pour terminer, je vais vous présenter une dernière fonctionnalité très pratique : le refactoring « intelligent ».
Commençons par le refactoring. SQL Server Database vous propose plusieurs types de refactoring :
- renommage du nom d'un objet ;
- renommage du schéma d'un objet ;
- remplacement des
SELECT*par la liste des colonnes de la table ; - remplacement du nom des objets par leur nom complet : [SCHEMA].[Table].[Colonne] .
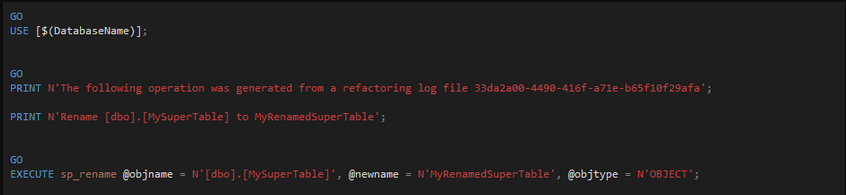
À première vue, très pratique, mais pas spécialement intelligent :). Eh bien en fait si ! Lors du renommage, un fichier .refactorlog va être créé. Ce fichier, qui est un fichier XML, va tracer l'ensemble des modifications de type refactoring demandées par l'utilisateur. Par exemple, sur la capture ci-dessous, j'ai renommé ma table « MySuperTable » en « MyRenamedSuperTable ».
|
|

De fait, au moment des comparaisons et des mises à jour (soit via l'outil de schema compare, soit via la publication), l'algorithme va détecter le renommage et va procéder à un renommage de la table et non à une suppression/recréation. On peut vérifier facilement cela en générant le script d'update à partir de l'outil de comparaison :
|
|
Nous avons fait le tour des principales fonctionnalités des projets de type SQL Server Database. Pour conclure, nous sommes face à un formidable et indispensable outil pour tout projet utilisant une ou plusieurs bases de données SQL Server. Les avantages sont multiples et les inconvénients inexistants. Il ne faut donc surtout pas hésiter à s'en servir, voire à l'intégrer dans un projet existant (il est possible de créer un projet à partir d'une base de données) !
VIII. Note de la rédaction de developpez.com ▲
Nous tenons à remercier Claude Leloup pour la relecture orthographique.